Interaction Network of the German Twittersphere
A Long-Term Observation

THIS PAGE IS TEMPORARY AND WILL BE UPDATED ACCORDINGLY AFTER PUBLICATION
Online social networks are ubiquitous, have billions of users, and produce large amounts of data. While platforms like Reddit are based on a forum-like organization where users gather around topics, Facebook and Twitter implement a concept in which individuals represent the primary entity of interest. This makes them natural testbeds for exploring individual behavior in large social networks. Underlying these individual-based platforms is a simple network whose "friend" or "follower" edges are of binary nature only. In this paper, we make use of the full information contained in tweet-retweet actions to explore further a framework of social connections, which, while disregarding the specificity of text content, incorporates information beyond pure binary edges labelling acquaintances. In particular, we define and weight social connectivity between pairs of users, keeping track of the frequency of shared content and the time elapsed between publication and sharing. Our framework is applied to one particular case of the German Twitter network from which we derive a large-scale interaction network. Moreover, we also present a preliminary topological analysis of the derived network. Finally, we discuss how to apply this framework as a ground basis for investigating spreading phenomena of particular contents - e.g., fake and real news - allowing to study the dynamics of information propagation in the underlying community of users.
Citation
@inproceedings{TODO}
Dataset Details
The data collection started in late 2019 and stretched to mid-2020. During this time, we analyzed more than one billion historical statuses from user timelines. Among them are 400 million tweets and 300 hundred million retweets. All statuses in total are written or shared by about 30 million users. The goal was to collect and analyze as much tweet and retweet metadata as possible.
Based on a set of 2638 Twitter accounts of German personalities close to politics that we derive from the Twitter lists in Table~\ref{tab:inital}, we first fetch a user's most recent 3,200 tweets and later \their first and second neighborhoods in the follower network. Subsequently, we analyze the most recent tweets of the newly acquired users, ignoring those that are not written either in German or in English. We repeated this process iteratively with users only tweeting in German until the number of newly added users decreased significantly.
One should note that the Twitter API only allows limited access to user data. Twitter's limit of only 3,200 tweets that are accessible for each user timeline implies that only a small portion of the tweets authored by highly active users contribute to our dataset. Moreover, Twitter allows its users to set their profiles to private, i.e.~allowing only direct followers to access that user's content. For that reason, data from private profiles is excluded from our consideration. Note that the work presented here examines the interaction that arises from the sharing of content. Users who have never retweeted another user are therefore not considered.
Terms of use
The use of the German interaction dataset is restricted to research and education purposes. The
use of the dataset is forbidden for commercial use without prior written permission. For other
purposes, contact us (see below). In all documents and publications that use the Wico-Graph
dataset or report experimental results based on the Wico-Graph dataset, a reference to
the dataset paper has to be included (see above). Please email daniels (_at_) simula (_dot_) no if you have any
questions regarding how to cite the dataset.
Visualisation
Illustration of a selection of the network that we present in the course of this work.
The illustration contains approximately 25,000 nodes and 300,000 edges. The process for
creating this illustration is as follows. First, we extract the main component, and transform
it into an undirected network. Second, we perform 10,000 breath first searches (BFS) among a
subset of 50,000 nodes of the main component. Here, the decision to choose 50,000 nodes is
a trade-off between acceptable runtime of Graphistry~\cite{graphistry_2019}, a commercial
tool for the visualisation of large networks that makes use of the
Forceatlas2 layouting algorithm, and an appropriate network size.
We performed the experiment several times with different numbers of BFS
runs showing 10,000 to be a number that results in an appropriate intersect
between the nodes of different experiments. Each BFS starts from a randomly
chosen but never from the same node. For each of the nodes visited in a BFS pass,
we update a counter resulting in a list of nodes, each of them assigned the number
of visits overall performed runs. The result is a statistic that keeps track of the
number of visits, overall 10,000 BFS runs, for each node of the main networks. Later,
in a third step, another batch of 10,000 BFS is performed to determine the network that
archived the highest average after summing up the node values. This process allows choosing
the sample with the most visited nodes, i.e.~most representative connected sample.
The node size reflects its degree, and its color corresponds to the number of visits
during step one. The brighter the color, the more often the node was visited.
Insights
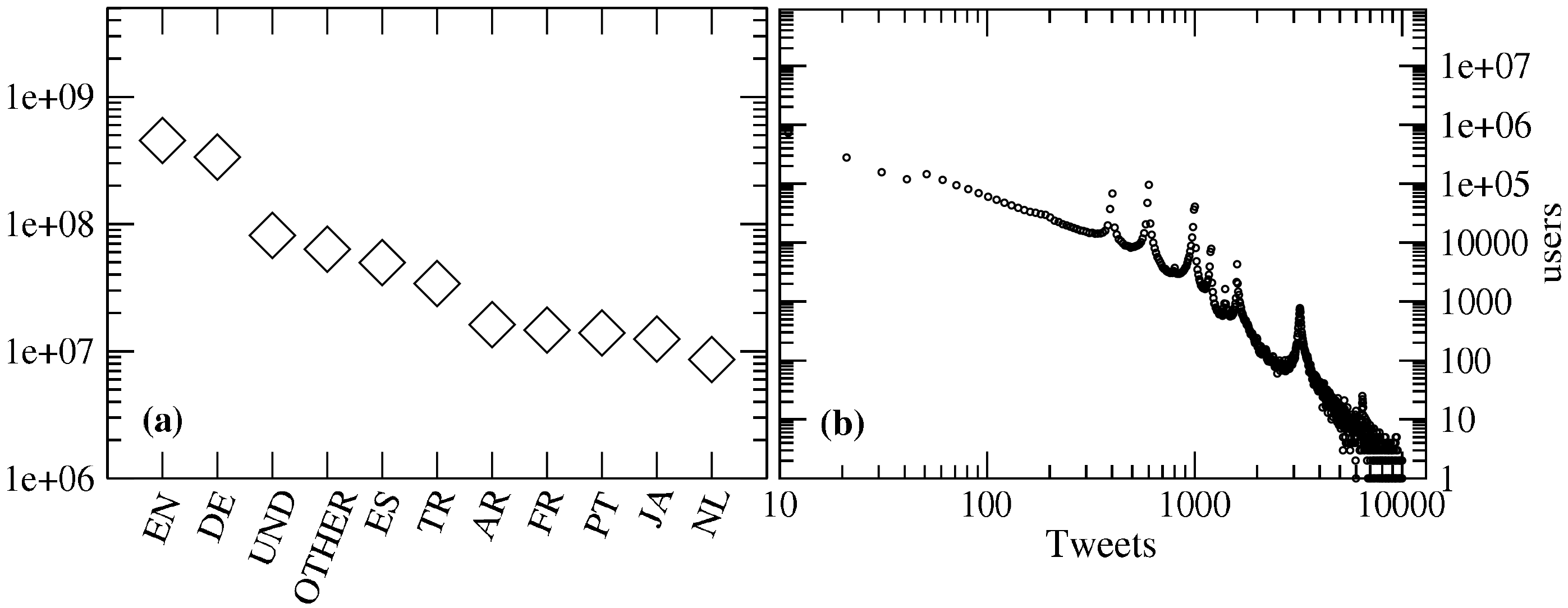
In total,
there are tweets in 28 different languages. The languages shown here are starting from the left:
EN = English,
DE = German,
UND = Undefined,
OTHER = Languages not listed,
ES = Spanish,
TR = Turkish,
AR = Arabic,
FR = French,
PT = Portuguese,
JA = Japanese and
NL = Dutch.
English, German and Undefined are the three dominating languages.
The dominance of German-language tweets is due to the analysis method,
which was geared towards the German-speaking world. The eighteen less
tweeted languages are summed up under the label OTHER. (b) Number of
tweets per user on a log scale. The picks can be explained by the collection
process. Each request to Twitter's API for user-timelines returns a batch.
The collection process is optimized for batch sizes and thus creates a binning.
Ethics approval
In this study, we used fully anonymized data approved by Privacy Data Protection Authority. It
was exempted from approval from the Regional Committee for of the Oslo Metropolitan University.
Contact
Email daniels (_at_) simula (_dot_) no if you have any
questions about the dataset and our research activities. We always welcome collaboration and
joint research!